Charger 1 million de lignes dans une base de données MySQL

Afin de tirer profit des meilleures performances des bases de données relationnelles, il est important de maîtriser les concepts les plus avancés de ces bases de données.
Depuis peu, je me suis donné comme tâche de maîtriser ces concepts avancés afin de créer des applications backend performantes. D'ailleurs, la maîtrise des bases de données est une compétence clé à ne pas ignorer quand on souhaite évoluer dans l'ingénierie backend.
L'une des ressources que j'ai utilisées principalement est ce cours de PlanetScale : MySQL for Developers.
Ce cours aborde plusieurs notions avancées et est très adapté pour les développeurs qui souhaitent améliorer leurs compétences en bases de données relationnelles, plus précisément avec le SGBD MySQL.
Mais pour mieux pratiquer les notions de ce cours telles que les index ou encore les techniques pour écrire des requêtes SQL efficaces, je devais avoir un grand jeu de données dans la base de données. C'est le seul moyen pour mesurer vraiment les performances d'une requête, car cela s'apparente à nos environnements de production.
Dans cet article, j'ai documenté les différentes étapes que j'ai suivies afin de charger un gros volume de données dans la DB.
Étape 1 : Constitution des données.
Pour avoir des données de test, il existe plusieurs plateformes. Il suffit juste d'effectuer une recherche de "generate random data" sur Google pour avoir plusieurs propositions.
Dans mon cas, j'ai utilisé : https://www.rndgen.com/data-generator.
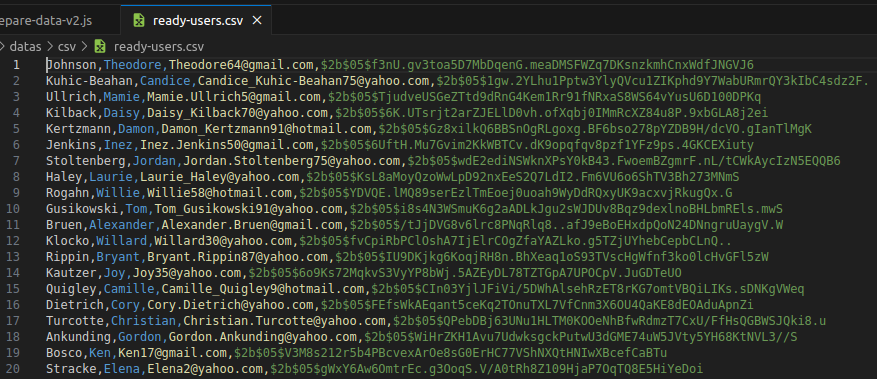
Je me suis limité à une structure de données plus basique : Prénom, Nom, Email & Mot de passe ; de quoi nous avons besoin pour enregistrer un utilisateur dans un système.

Voici quelques contraintes de base que je me suis imposé afin de rendre la tâche plus réaliste à un besoin d'entreprise.
- Bien que la plateforme me propose d'appliquer un hash au mot de passe, j'ai préféré le générer en clair et d'y appliquer moi-même un hashage en utilisant un outil familier. En situation d'entreprise, on peut avoir ce cas d'usage où on aura besoin de créer des comptes utilisateurs de façon automatisée avec des mots de passe par défaut. Si les données sont déjà hashées lors de la génération de données, il ne sera plus possible d'avoir la valeur claire de ces mots de passe.
- Le format des données générées sera du JSON. Cela me permettra de comprendre comment on peut passer d'un fichier JSON à un fichier CSV avant traitement.
Pour un début, je me suis limités à générés 1 000 000 lignes de données utilisateurs.
Voici un résumé de la configuration pour la génération des données de tests

Pour résumer cette première étape, nous disposons d’un fichier JSON contenant un million de lignes de données, pour une taille d’environ 157 Mo, à insérer dans la base de données.
Deux options s’offrent alors à nous:
- Créer un script qui lit le fichier JSON et insère les données progressivement dans la base. Cela implique d’installer des bibliothèques externes pour établir la connexion et gérer les transactions avec MySQL.
- Utiliser une instruction native de MySQL :
LOAD DATA. Cette commande permet de charger d’un seul coup un fichier CSV dans la base de données, sans avoir besoin d’écrire un script ou d’installer une bibliothèque supplémentaire. Un vrai gain de temps.
Dans ma progression, j’ai choisi d’exploiter la deuxième technique. Mais avant de pouvoir l’appliquer, il faut d’abord transformer le fichier JSON en un fichier CSV, afin de le rendre compatible avec l’instruction LOAD DATA.
(La contrainte évoquée précédemment prend maintenant tout son sens 😄)
Etape 2: Pré-traitement des données
Le pré-traitement se compose de deux tâches principales :
- Conversion des données JSON en CSV
- Hashage du mot de passe à l’aide de bcrypt
Avant d’obtenir le script final de traitement des données, j’ai procédé par itérations.
Pour la première version, j’ai souhaité tester mes connaissances en m’appuyant uniquement sur les fonctionnalités natives de Node.js, sans utiliser de bibliothèque externe. L’objectif était de :
- Utiliser les streams pour une lecture progressive, car il était impossible de charger l’intégralité du fichier en mémoire ;
- Lire le fichier caractère par caractère, afin d’identifier chaque élément du tableau JSON de manière précise.
Cette première itération ne comprenait pas encore le hashage des mots de passe, que j’ai volontairement omis à ce stade.
Voici le script de cette première version :
const fs = require("node:fs");
const { Transform } = require("node:stream");
const { resolve } = require("node:path")
const jsonSource = resolve(__dirname, "../datas/raw-json/", "raw-users.json");
const csvFile = resolve(__dirname, "../datas/csv/", "ready-users.csv");
const dataCSVFile = fs.createWriteStream(csvFile);
const rawUserFile = fs.createReadStream(jsonSource, {
highWaterMark: 1,
encoding: "utf-8",
});
function isValidJSON(potentialJSON = "") {
try {
JSON.parse(potentialJSON);
return true;
} catch (e) {
return false;
}
}
class DataProcessor extends Transform {
#currentJSON;
constructor() {
super();
this.#currentJSON = "";
}
_transform(chunk, encoding, callback) {
const value = chunk.toString();
if (value === "\n") return callback();
// Detect new JSON Start
if (value === "{") {
this.#currentJSON = value;
return callback();
}
// Detect new JSON End
if (value === "}") {
this.#currentJSON += value;
if (!isValidJSON(this.#currentJSON)) {
console.warn("Invalid JSON", this.#currentJSON);
this.#currentJSON = "";
return callback();
}
const data = JSON.parse(this.#currentJSON);
console.log(data);
const csvRow = `${data.lastname},${data.firstname},${data.email},${data.password} \n`;
this.push(csvRow);
this.#currentJSON = "";
return callback();
}
this.#currentJSON += value;
callback();
}
}
rawUserFile.pipe(new DataProcessor()).pipe(dataCSVFile);
Après un premier test avec cette V1, plusieurs limites sont vite apparues — la principale étant la lenteur du traitement, due à la lecture caractère par caractère.
Avec l’aide de ChatGPT, j’ai pu améliorer le script pour le rendre plus efficace. Dans cette nouvelle version, j’ai utilisé le package split2 (https://www.npmjs.com/package/split2), qui permet une lecture ligne par ligne lors du streaming du fichier JSON. J’y ai également intégré bcrypt afin de procéder au hashage des mots de passe.
Voici la version 2 du script :
const fs = require("node:fs");
const { Transform, pipeline } = require("node:stream");
const split2 = require("split2");
const { resolve } = require("node:path")
const { hashSync } = require("bcrypt");
const jsonSource = resolve(__dirname, "../datas/raw-json/", "raw-users.json");
const csvFile = resolve(__dirname, "../datas/csv/", "ready-users.csv");
const dataCSVFile = fs.createWriteStream(csvFile);
const rawUserFile = fs.createReadStream(jsonSource, {
start: 1, // Ignore start "["
highWaterMark: 16 * 1024,
encoding: "utf-8",
});
let i = 0;
class DataProcessor extends Transform {
constructor() {
super({ readableObjectMode: true });
this.currentJSON = "";
}
_transform(chunk, _encoding, callback) {
this.currentJSON += chunk.toString().trim();
try {
if (this.currentJSON.endsWith("},")) {
// Remove last comma
this.currentJSON = `${this.currentJSON.slice(0, -2)}}`;
}
const data = JSON.parse(this.currentJSON);
this.currentJSON = "";
data.password = hashSync(data.password, 5);
const csvRow = `${data.lastname},${data.firstname},${data.email},${data.password}\n`;
this.push(csvRow);
i++;
console.log(`Record ${i}:`, `${data.lastname} ${data.firstname}`)
} catch (e) {
// Don't listen format error.
if (!(e instanceof SyntaxError)) {
console.log("Error", e)
console.warn("Invalid JSON", this.currentJSON);
this.currentJSON = "";
}
}
return callback();
}
}
pipeline(
rawUserFile,
split2(), // Read file line by line, to improve execution speed
new DataProcessor(),
dataCSVFile,
(err) => {
if (err) {
console.error("Failed to prepare data:", err);
} else {
console.log("All data are processed.");
}
}
);Avec cette nouvelle version du script, le pré-traitement a été considérablement accéléré par rapport à la version précédente. Pour un fichier de 1 million de lignes, le traitement complet des entrées a pris 37 minutes et 44 secondes.
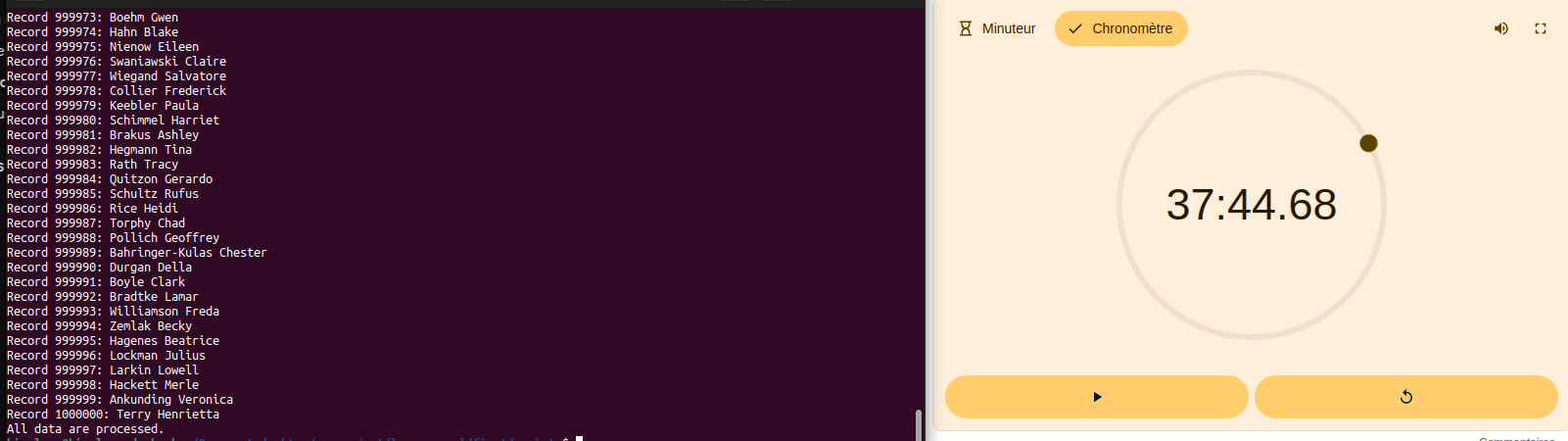
Il s'agit également d'un traitement assez gourmand en ressources
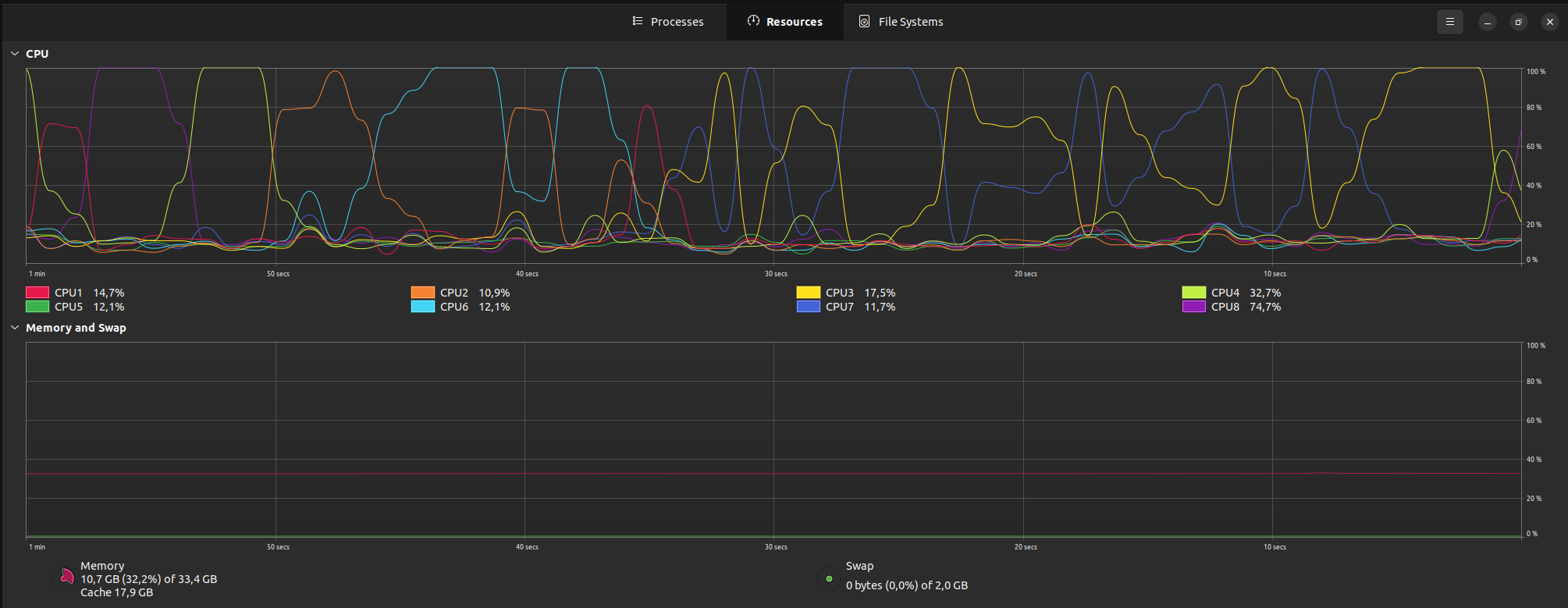
Nous pourrions rendre le flux de traitement du fichier JSON beaucoup plus performant en utilisant ce package adapté : stream-json.
Maintenant que nous avons réussi à obtenir un jeu de données conforme à l'instruction SQL de chargement, nous allons passer à l'étape 3, qui consiste à insérer les données dans la base de données.
Etape 3: Insertion des données
Ci-dessous vous trouverez le DDL de cette table:
CREATE TABLE `users` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT,
`firstname` varchar(50) NOT NULL,
`lastname` varchar(50) NOT NULL,
`email` varchar(100) NOT NULL,
`password` varchar(128) NOT NULL,
PRIMARY KEY (`id`)
);Voici l'instruction SQL complète utilisée pour charger les données dans la table.
LOAD DATA LOCAL INFILE '/absolute/path/datas/csv/ready-users.csv'
INTO
TABLE users
FIELDS
TERMINATED BY ','
OPTIONALLY ENCLOSED BY '"'
LINES
TERMINATED BY '\n'
(@lastname,
@firstname,
@email,
@hashed_password)
SET
firstname = @firstname,
lastname = @lastname,
email = @email,
password = @hashed_passwordCette instruction permet d'importer rapidement des données depuis un fichier local dans une table MySQL. Voici son principe de fonctionnement :
- Elle lit les données ligne par ligne depuis un fichier texte (généralement CSV ou TSV).
- Elle les insère dans une table MySQL spécifiée.
- Elle est beaucoup plus rapide qu'une série d'instructions INSERT (Vraiment rapide. Voir un peu plus bas les stats).
Principales options :
FIELDS TERMINATED BYdéfinit le séparateur de colonnes (virgule, tabulation, etc.) Dans notre cas actuel, c'est la virgule:,LINES TERMINATED BYindique le séparateur de lignes: le saut de ligne :\nIGNORE n LINESpermet d'ignorer les premières lignes (utile pour les en-têtes). Mais nous n'en avons pas dans notre fichier actuel.
Point important à noter : l'option LOCAL indique que le fichier se trouve sur la machine cliente, et non sur le serveur MySQL. Pour des raisons de sécurité, cette fonctionnalité peut être désactivée selon la configuration du serveur, ce qui était le cas pour moi. Pour l'activer, j'ai dû exécuter l'instruction supplémentaire suivante :
SET GLOBAL local_infile = TRUE;Si vous souhaitez en savoir plus sur cette instruction, vous pouvez consulter la documentation officielle de MySQL : https://dev.mysql.com/doc/refman/8.4/en/load-data.html.
Comme vous pouvez le constater dans la capture suivante, l'insertion d'un million de lignes dans la table a pris 26 secondes. Si nous avions dû effectuer une insertion ligne par ligne avec une instruction SELECT habituelle, cela aurait pris environ 40 minutes et aurait nécessité l'installation de bibliothèques supplémentaires.
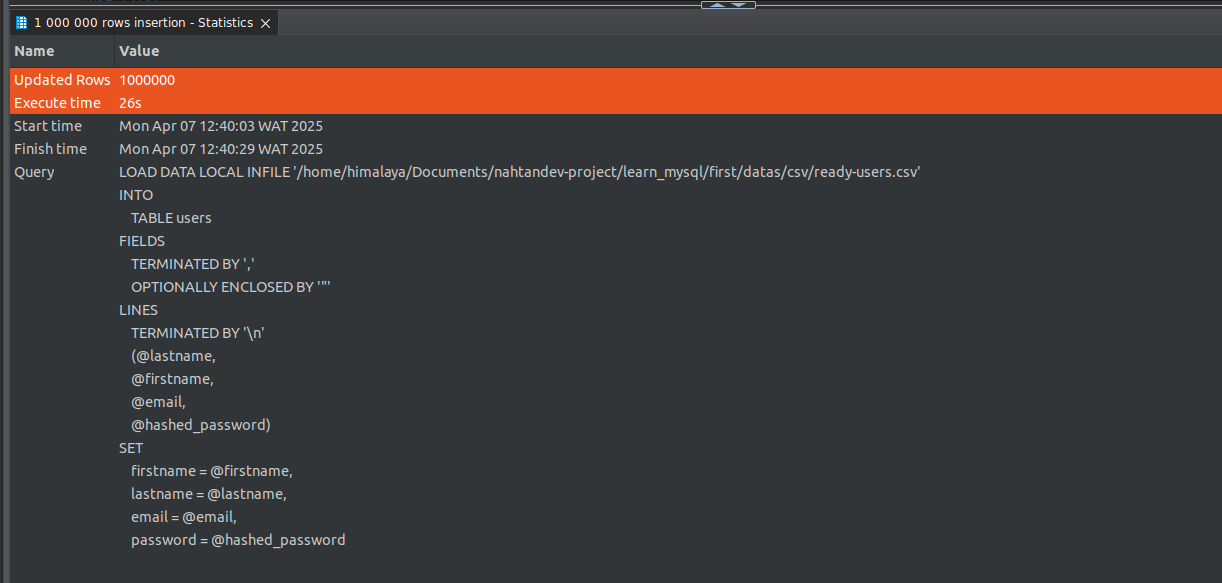
Pourquoi 40 minutes environ, alors que nous ne l'avons pas encore testé ? ****
La raison est que si nous devions le tester, cela aurait dû être fait lors de l'étape de pré-traitement des données mentionnée précédemment. Après la lecture d'une ligne du fichier JSON et le hachage du mot de passe, l'insertion aurait été effectuée directement dans la table à l'aide d'une bibliothèque cliente ou d'un ORM, sans avoir besoin de sauvegarder la sortie dans un fichier .csv
Conclusion
Si vous souhaitez insérer un grand nombre de données dans une base de données MySQL, LOAD DATA reste la meilleure approche.
Ressources
- PlanetScale Youtube Tutorial: I loaded 100,000,000 rows into MySQL (fast)
- Scripts: https://gist.github.com/nahtandev/a439ed7dba56c9f76d60bbd7e9652392
Crédits
- Image de couverture générée avec Coverview